OEM version of the LSI SAS 9211-8i, such as the Dell H200, H310 or IBM M1015 are quite popular for use with FreeNAS. However, they need to be flashed with a regular LSI firmware to disable their RAID capabilities in order to passthrough the drives directly to the OS.
Here’s how I upgraded my Dell PERC H200, which came with Dell’s A10 firmware (equivalent to LSI SAS 2008 P07 firmware), to LSI P20 firmware. The newer version also has the advantage that drives larger than 2TB are supported. Also, re-flashing allowed me to not flash a boot ROM to the card, speeding up the boot process of my server as my boot disk is connected to the Intel AHCI controller on the mainboard.
Please note that this operation is not supported by Dell or LSI, may void your warranty and could potentially damage the controller. So proceed at your own risk.
Step 1: Downloading old firmware
- Download the firmware for the Dell 6Gbps SAS HBA (this is a variant of the H200 with 8 external ports instead of 8 internal ports) and extract 6GBPSAS.FW from SASHBA_Firmware_6GBPS-SAS-HBA_07.03.06.00_A10_ZPE.exe.
- Download the P07 firmware for the LSI SAS 9211-8i and extract the file 2118it.bin from 9211_8i_Package_For_P7_Firmware_BIOS_Upgrade_on_MSDOS_and_Windows.zip.
- Download the P05 UEFI flasher for the LSI SAS 9211-8i and extract the file sas2flash.efi from EFI_Installer_P5.zip.
- Place these three files into a directory named P07 on a FAT32-formatted USB flash drive.
Step 2: Downloading current firmware
- Download the current firmware for the LSI SAS 9211-8i and extract the file 2118it.bin from 9211_8i_Package_P20_IR_IT_Firmware_BIOS_for_MSDOS_Windows.
- Download the current UEFI flasher for the LSI SAS 9211-8i and extract the file sas2flash.efi from Installer_P20_for_UEFI.zip.
- Place these two files into a directory named P20 on the USB flash drive.
Step 3: Downloading UEFI shell
- Download an x86_64 UEFI shell. I had to use the v1 shell because my server would only show error messages (about failed assertions and files not found).
- Rename the shell to BOOTX64.efi and place it into a directory named BOOT inside a directory named EFI on the USB flash drive.
Step 4: Flashing
- UEFI boot your server off the flash drive
- Type map -b to find the flash drive
- Switch to it, e.g. by entering fs1:
- cd P07
- sas2flash.efi -listall should show you your controller
- sas2flash.efi -c 0 -list shows you details on the controller. Note down the SAS address in case something goes wrong and you need to reprogram the SAS address.
- Erase the old firmware and boot ROM: sas2flash.efi -o -e 6
- Write the Dell 6Gbps firmware: sas2flash.efi -o -f 6GBPSAS.FW
- Write the LSI P07 firmware: sas2flash.efi -o -f 2118it.bin
- cd ..\P20
- Write the LSI P20 firmware: sas2flash.efi -o -f 2118it.bin
Notes
At the end of every command (before I rebooted before step 10), I got the message “Failed Reconnecting the EFI Driver. (EFI Error: Not Found)”. It did not seem to affect anything.
Step 7 showed “Erasing Flash Region” and then after a while “ERROR: Erase Flash Operation Failed!”. I simply proceeded and the error did not appear to affect anything.
Step 8 looked like this:
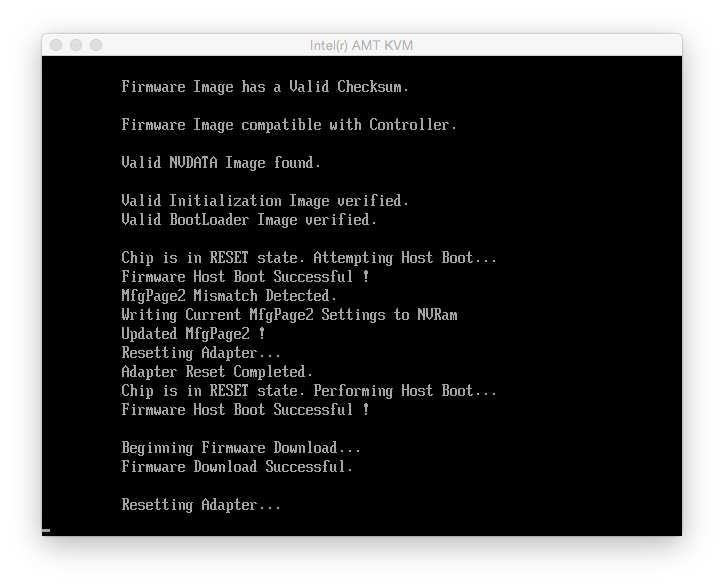
and the controller details after the flash looked like this:
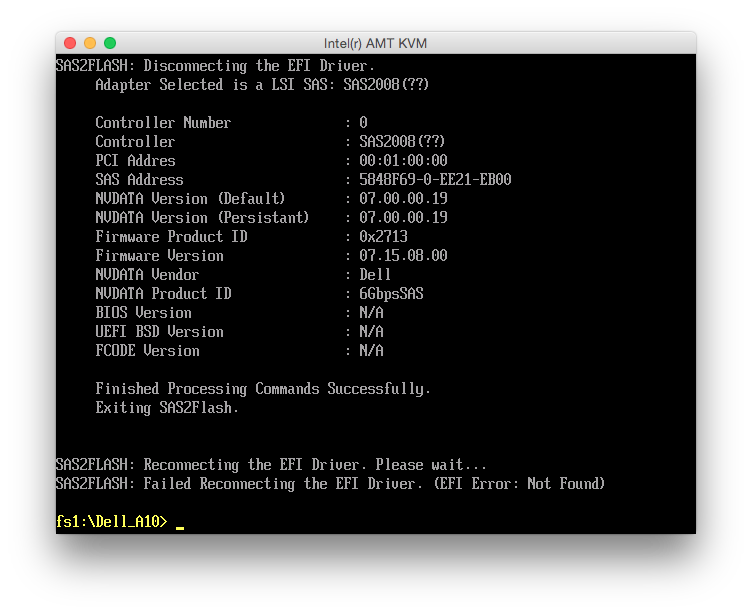
During step 9, I received the message “NVDATA Versions Compatible. NVDATA Product ID and Vendor ID do not match. Would you like to flash anyway [y/n]?”, where I simply hit y and it proceeded flashing. At the end, it said “Firmware Flash Successful! Resetting Adapter… Adapter Reset Failed!”. Looking at the controller details showed lots of errors:
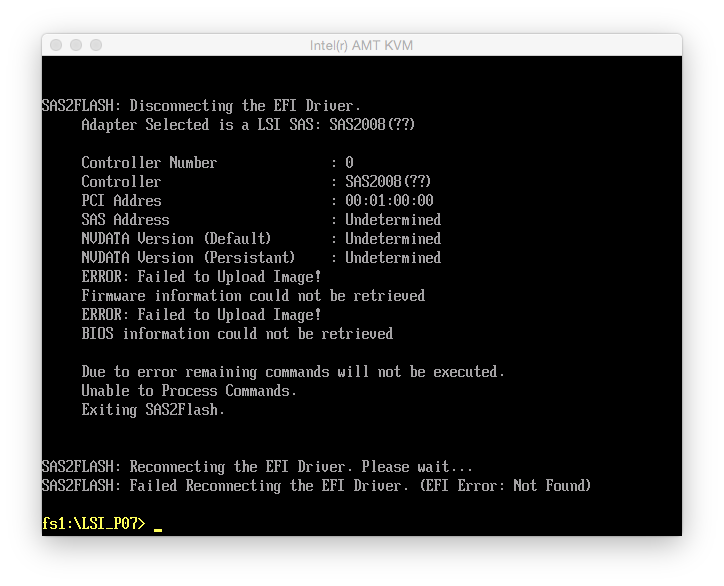 So at this point, I rebooted the machine. Now the details looked all right:
So at this point, I rebooted the machine. Now the details looked all right:
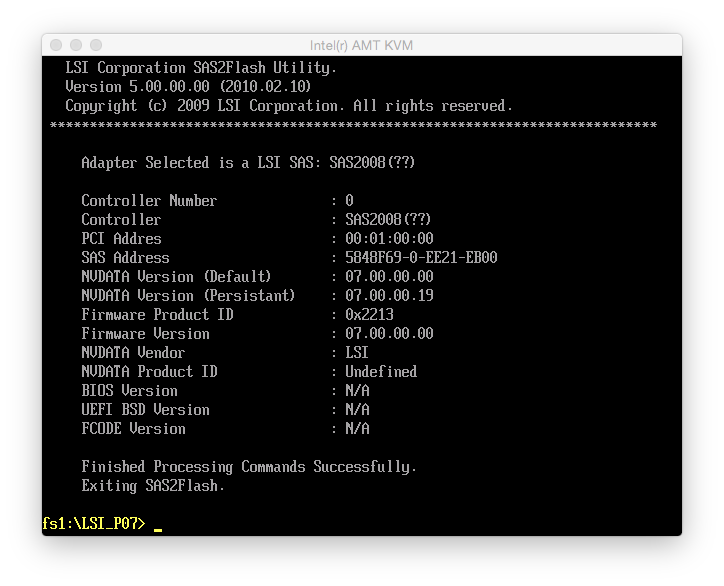
Step 11 worked without a hitch and afterwards the controller details looked like this:
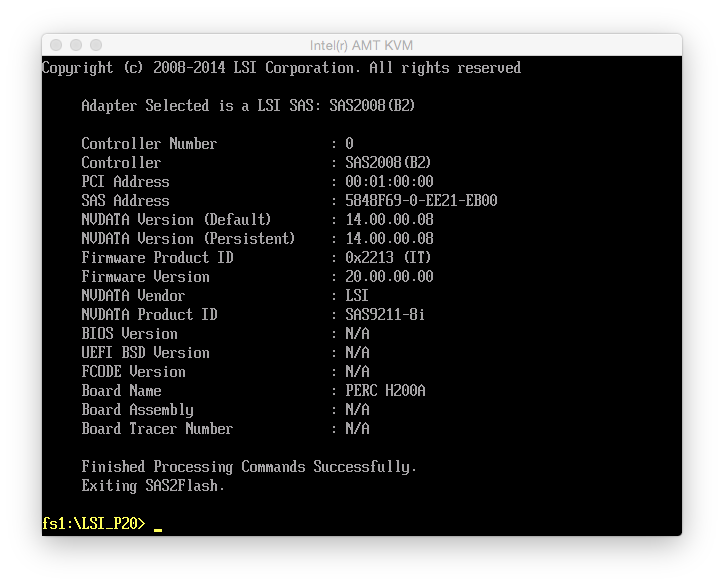
Booting up the server, I now had a Dell H200 that behaved exactly like a LSI SAS 9211-8i. The only difference was that it still reported its name and PCI ID (1028:1f1c) as a Dell 6Gbps SAS Card. FreeNAS didn’t care about that though.
Addendum: Matching firmware and driver versions
I was using this controller with FreeNAS 9.2.1.9 and kept on getting kernel messages like
Nov 30 19:49:55 file02 kernel: (da1:mps0:0:0:0): READ(10). CDB: 28 00 a1 ea 00 58 00 01 00 00 length 131072 SMID 609 terminated ioc 804b scsi 0 state 0 xfer 0
Nov 30 19:49:55 file02 kernel: (da1:mps0:0:0:0): READ(10). CDB: 28 00 a1 e9 ff 58 00 01 00 00
Nov 30 19:49:55 file02 kernel: (da1:mps0:0:0:0): CAM status: SCSI Status Error
Nov 30 19:49:55 file02 kernel: (da1:mps0:0:0:0): SCSI status: Check Condition
Nov 30 19:49:55 file02 kernel: (da1:mps0:0:0:0): SCSI sense: ABORTED COMMAND asc:47,3 (Information unit iuCRC error detected)
Nov 30 19:49:55 file02 kernel: (da1:mps0:0:0:0): Retrying command (per sense data)
It turns out that these are due to a mismatch between firmware and driver version. FreeBSD 9 ships with driver version 16 and FreeBSD 10 includes version 19. Linux currently has version 18. So make sure that in step 11, you always flash the version that matches your operating system’s driver version, don’t blindly go with version P20 or the latest version. On FreeNAS, you can determine the driver version using dmesg | grep “mps0: Firmware”:
mps0: Firmware: 20.00.00.00, Driver: 16.00.00.00-fbsd
In this case, I had no data loss whatsoever and the person who reported this on the FreeBSD mailing list didn’t either, but both LSI and FreeBSD recommend to keep driver and firmware in sync.
Downgrading firmware
As I had to downgrade the firmware, I needed to do sas2flash.efi -o -e 6 before the flashing. Of course, this means that the crossflashing is undone and you’ll have to start over, flashing Dell 6GPBSAS.FW, flashing LSI P07 IT, and finally flashing the version matching your driver.
6GBPSAS.FW and LSI P07 need to be flashed with the LSI P05 sas2flash.efi because later versions will simply refuse when they encounter a NVDATA mismatch. Once that’s done, you can use the latest (P20 at the moment) sas2flash.efi to flash your final firmware version. This also has the advantage that you don’t get these “Adapter Reset Failed” warnings.
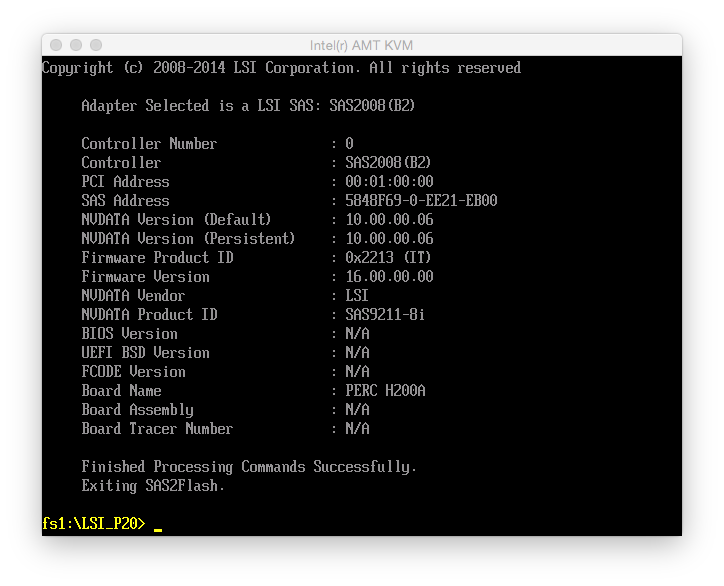
Below is a screenshot of the details of the P16 firmware:
Update 2021: Over the years, LSI was taken over by Broadcom, Broadcom was taken over by Avago, and Avago renamed itself back to Broadcom. As a result, none of the download links above work anymore. The files are still available from Broadcom though: go to https://www.broadcom.com/support/download-search, select “Legacy Products”, “All Legacy Products”, search for 9211-8i.
