At the university lab I work at, we usually get desktop computers with Intel Core i7 Extreme CPUs. They have more memory controllers and more cores than Intel’s mainstream CPUs, which is great for us because we do software development and simulations on these machines. Now that it was time to order some new machines, we decided to check out what AMD offers. The last time AMD’s Athlon series was competitive with Intel in the high-end desktop market was probably in the days before the Core i series was introduced a decade ago. Even in the server/HPC market, AMD’s Opteron series hadn’t been a serious Intel competitor after 2012. Now with the Ryzen, AMD finally has something that beats Intel’s high-end offerings both in absolute price and in price per performance.
Today’s high-end CPU market
As prices on Intel’s high-end chips seem to have been increasing with every generation and after Intel didn’t handle the Spectre/Meltdown disaster very well at all earlier this year, we decided that it really was time to break Intel dominance in our lab. I would actually have liked to get something with a non-x86 architecture (because why not), but the requirement of eight CPU cores and four DDR4 memory channels ruled out pretty much everything. The remaining ones were either eliminated based on price (the IBM POWER9 CPU as in the Talos II) or because they are not available in the market (ARM in the form of the Cavium ThunderX2 or Qualcomm Centriq). The POWER9 and ThunderX2 actually have eight memory channels (the Talos’s mainboard only provides access to four though), as does the AMD Epyc (the server version of the Threadripper), so they or their successors might still become interesting options in the future. For comparison, Intel’s current Xeon Scalable series only has six channels, as does the Centriq.
The AMD Ryzen family
We decided to order a Threadripper 1950X with 16 cores. When I unpacked it and started my first benchmark simulation, I was pretty disappointed by the performance though. It turned out that the Threadripper is a NUMA architecture, but you need to toggle a BIOS option (set Memory Interleave to Channel) before it actually presents itself as such to the operating system. In its default mode, memory latencies are very high because a process might be running on a CPU core that is using memory on the other pair of memory controllers. The topology it presents in NUMA mode is roughly like this: out of the 16 cores, four cores each share a common L3 cache to make what AMD calls a core complex (CCX). Two CCXes together share a two-channel memory controller and sit on the same die. Two dies are interconnected with a 50 GB/s link. In NUMA mode and after setting the correct CPU affinity on my simulation processes (which is what the remaining sections of this blog post will be about), I was getting the expected performance — and as you might have expected, the Threadripper really is powerful. You can get something comparable from Intel, the Core i9 Extreme, but these chips are extreme not only in name but also in price. Also, I love the simplicity of AMD’s product lineup: the Ryzen series has two memory channels and 4-8 cores (i.e. one CCX), the Ryzen Threadripper has four memory channels and 8-16 cores (two CCX) and the Epyc has eight memory channels and up to 32 cores. Don’t bother with the second-generation Threadripper that were just announced: the 2920X is almost identical to the 1920X and the 2950X to the 1950X. The 2970WX and 2990WX are really odd chips: they have four CCXes (like the Epyc), but two of them don’t have their own memory controllers. So half of these chips would be as fast as my 1950X in NUMA mode, and the other half would be slower than my 1950X in its default mode.
CPU affinity for MPI
Usually, you only have to worry about CPU pinning and process affinity on servers, high-performance compute clusters and some workstations. Since AMD introduced the Opteron and Intel introduced the Core architecture, machines with multiple processor sockets have been associating memory controllers with CPUs in such a way that memory access within a socket was fast and between sockets was slower. This is called NUMA. To minimize inter-socket memory accesses, you need to tell your operating system’s scheduler to never move threads or processes between cores. This is called pinning or affinity. On servers, it is usually taken care of by the application, while on HPC clusters the admin configures the MPI library to do the right thing. The Threadripper is probably the first chip that brings NUMA to the desktop market.
If you are using OpenMPI, you just need to set two environment variables
export OMPI_MCA_hwloc_base_binding_policy=numa
export OMPI_MCA_rmaps_base_mapping_policy=numa
so that processes are pinned (bound) to a NUMA domain (usually that’s a socket, but in the Threadripper it’s a die with two CCXes). The second variable tells OpenMPI to create (map) processes on alternating NUMA domains — so the first one is put on the first die, the second one on the second die, the third one on the first die, and so on.
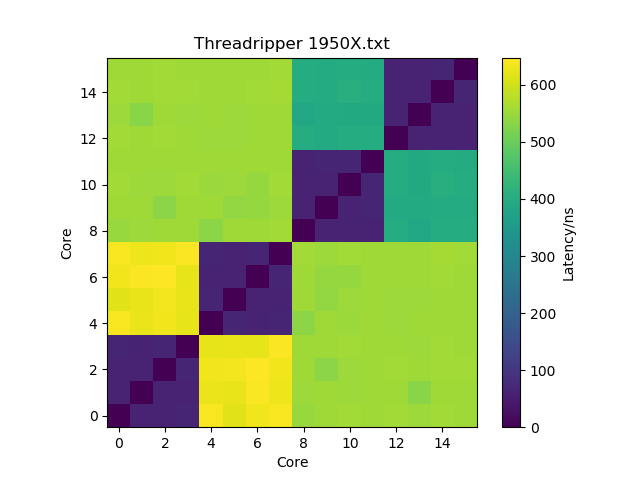
You can also use the -bind-to core and -map-by core command-line arguments to mpiexec/mpirun to achieve the same. Using l3cache instead of numa may actually get you some even better performance because latencies within a CCX are lower than between CCXes within a die, but that only gains you a few percent and requires that you use more processes and less threads, which may be suboptimal for some software. Below is an interesting figure about latency between cores, as measured with this tool (I’m not sure about the yellow squares though — I would have expected them to be more turquoise, and they don’t seem to match what I observe in actual performance).
If you are using Intel MPI (some commercial software we use does that), you only need
export I_MPI_PIN_DOMAIN=numa
to get pinning. The process creation already happens on alternating domains by default.
I like to put these variables in a file in /etc/profile.d so that they are automatically set for everyone who logs into these machines. I didn’t know this before, but both the GNU and the Intel OpenMP library will only create one thread for each core from their affinity mask, so you don’t even need to set OMP_NUM_THREADS=8 manually if you are running hybrid-parallelized codes.
CPU affinity with HTCondor
Our machines run 24 hours a day, 365 days a year. When nobody is using them locally or via SSH, they run simulation jobs via the HTCondor job scheduler. Of course, we want to make good use of the resources with these jobs too, so we need CPU pinning as well. Usually, we set
NUM_SLOTS = 1
NUM_SLOTS_TYPE_1 = 1
SLOT_TYPE_1 = cpus=100%
SLOT_TYPE_1_PARTITIONABLE = true
in our Condor configuration so that people can decide themselves how many CPUs they want for their jobs. For the Threadripper, it doesn’t make sense to use more than 8 cores per job because we don’t want jobs to cross NUMA domains. This means we need two slots with 50% of the CPU cores, and we want to set SLOT<n>_CPU_AFFINITY to pin the processes to the die. I wrote a Jinja2 template that creates this Condor configuration:
{%- set nodes = salt.file.find('/sys/devices/system/node', name='node[0-9]*', type='d') -%}
NUM_SLOTS = {{ nodes | count }}
ENFORCE_CPU_AFFINITY = True
{% for node in nodes -%}
NUM_SLOTS_TYPE_{{ loop.index }} = 1
{%- set cpus = salt.file.find(node, name='cpu[0-9]*', type='d') -%}
{%- set physical_cpus = [] -%}
{% for cpu in cpus %}
{%- set cpu_id = cpu.replace(node + '/cpu', '') -%}
{%- set siblings = salt.file.read(cpu + '/topology/thread_siblings_list').strip().split(',') -%}
{% if cpu_id == siblings[0] %}
{%- do physical_cpus.append(cpu) -%}
{% endif -%}
{% endfor %}
SLOT_TYPE_{{ loop.index }} = cpus={{ physical_cpus | count }}
SLOT_TYPE_{{ loop.index }}_PARTITIONABLE = true
{%- set cpu_ids = [] -%}
{% for cpu in cpus %}
{%- do cpu_ids.append(cpu.replace(node + '/cpu', '')) -%}
{% endfor %}
SLOT{{ loop.index }}_CPU_AFFINITY = {{ cpu_ids | join(',')}}
{% endfor -%}
If you don’t have a Jinja2-based configuration manager like SaltStack, you can use the following Python script to render the template:
import os, sys
from jinja2 import Environment, FileSystemLoader
import salt
import salt.modules.file
salt.file = salt.modules.file
file_loader = FileSystemLoader(os.path.dirname(__file__))
env = Environment(loader=file_loader, extensions=['jinja2.ext.do'])
template = env.get_template(sys.argv[1])
template.globals['salt'] = salt
print (template.render())
This produces
NUM_SLOTS = 2
ENFORCE_CPU_AFFINITY = True
NUM_SLOTS_TYPE_1 = 1
SLOT_TYPE_1 = cpus=8
SLOT_TYPE_1_PARTITIONABLE = true
SLOT1_CPU_AFFINITY = 0,1,16,17,18,19,2,20,21,22,23,3,4,5,6,7
NUM_SLOTS_TYPE_2 = 1
SLOT_TYPE_2 = cpus=8
SLOT_TYPE_2_PARTITIONABLE = true
SLOT2_CPU_AFFINITY = 10,11,12,13,14,15,24,25,26,27,28,29,30,31,8,9
One additional complication is that some of our users like to set getenv = True in their condor submit file. This means that the variables we set in the global shell profile in the previous section are inherited to the Condor job, overriding the affinity we set for the slots. So we need a job wrapper script that removes these variables if present. Put
#!/bin/bash
for var in $(/usr/bin/env | /bin/grep -E '^(OMPI_|I_MPI_)' | /usr/bin/awk -F = {print $1}'); do
echo "Removing environment variable $var" >&2
unset "$var"
done
exec "$@"
error=$?
echo "Failed to exec($error): $@" > $_CONDOR_WRAPPER_ERROR_FILE
exit 1
into /usr/lib/condor/libexec/condor_pinning_wrapper.sh and add
USER_JOB_WRAPPER = /usr/lib/condor/libexec/condor_pinning_wrapper.sh
to your Condor configuration.
Update 2019-01: Updated the Jinja template to work correctly on non-16-core Threadrippers. These have one (12-core, 24-core) or two (8-core) cores disabled on each CCX, which results in non-consecutive core IDs.